
立即登录
v1.2.5
Takeaway:
Soft‑towel Folding: Disturbances in Stage‑1 (initial grasp) and Stage‑2 (pre‑fold) each retain 90% success.
Dynamic Unscrewing: Up to 4 s of reverse force during twisting and critical visual alignment—100% success; stable recovery.
Dynamic Push‑T: Multiple drag‑style disturbances during pushing—100% success.
Overall: 95.0% average success across tested scenarios, indicating reliable recovery under unstructured perturbations.
Takeaway:
Dynamic Push‑T: Large friction changes—100%; added distractor shapes—80%.
Agile Bowling: Floor property changes—100%.
Pouring: Granular (nuts) → liquid (water)—90%.
Folding: Unseen towel shape-80%.
Average 90.0% success across four change types without retraining.
Takeaway:
Soft‑towel Folding: New towel materials—100%.
Agile Bowling: Inverted pin arrangement—100%.
Pouring: New container geometry—60%.
Average 86.7% with only 1–3 hours of additional training.
Takeaway:
The policy achieves consistent 100% success after approximately 200 episodes of on-policy rollouts.
Takeaway:
1) he robot achieved more successful bowling trials than the five human participants under the same number of attempts, 25 successful trials (robot) vs. 14 successful trials (human).
2) For Push-T, the robot achieved more successful trials than expert human and beginner human at the same wall-clock time, 20 successful trials (robot) vs. 17 successful trials (expert) vs. 13 successful trials (beginner).
Takeaway:
1) Execution Efficiency: CM (RL) > DDIM (RL) > DP3 (IL) > DP (IL)
2) Single action vs. action chunking: single-step control mode is used when a fast closed-loop reaction is required
while action chunking is preferred for coordination-heavy or high precision tasks where smoothing mitigates jitter and limits error compounding.
* Execution efficiency is defined as the robot’s average task completion time. For fair comparison, we report this metric only on action-chunking tasks.
Single-step control (DDIM/CM) operates at the same inference rate, system-capped at 30 Hz (e.g., by the L515 camera),
so runtime is dominated by hardware rather than algorithmic differences.
Takeaway:
1) Variance clipping is valid for stable exploration - variance clipping in the stochastic DDIM sampling process.
2) Reconstruction is crucial for visual robotic manipulation RL as it mitigates representational drift and improves sample efficiency.
3) CM effectively compresses the iterative denoising process without sacrificing control quality, enabling high-frequency deployment.
4) On a relatively clean scene - the 3D variant learns faster and attains a higher final success rate.
5) Epsilon prediction is more suitable for RL: large noise schedule for exploration.
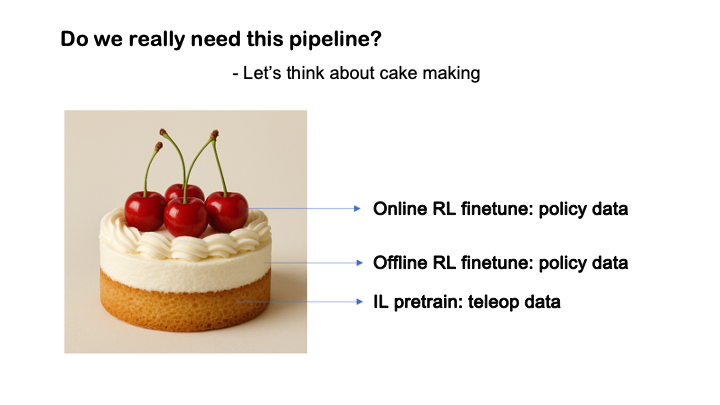
Takeaway:
Training robots is like baking a cake: demonstration learning (IL) forms the sponge base, offline reinforcement learning adds the rich cream layer, and online reinforcement learning crowns it all as the cherry on top.